this post was submitted on 27 Dec 2023
1298 points (95.9% liked)
Microblog Memes
5030 readers
350 users here now
A place to share screenshots of Microblog posts, whether from Mastodon, tumblr, ~~Twitter~~ X, KBin, Threads or elsewhere.
Created as an evolution of White People Twitter and other tweet-capture subreddits.
Rules:
- Please put at least one word relevant to the post in the post title.
- Be nice.
- No advertising, brand promotion or guerilla marketing.
Related communities:
founded 1 year ago
MODERATORS
you are viewing a single comment's thread
view the rest of the comments
view the rest of the comments
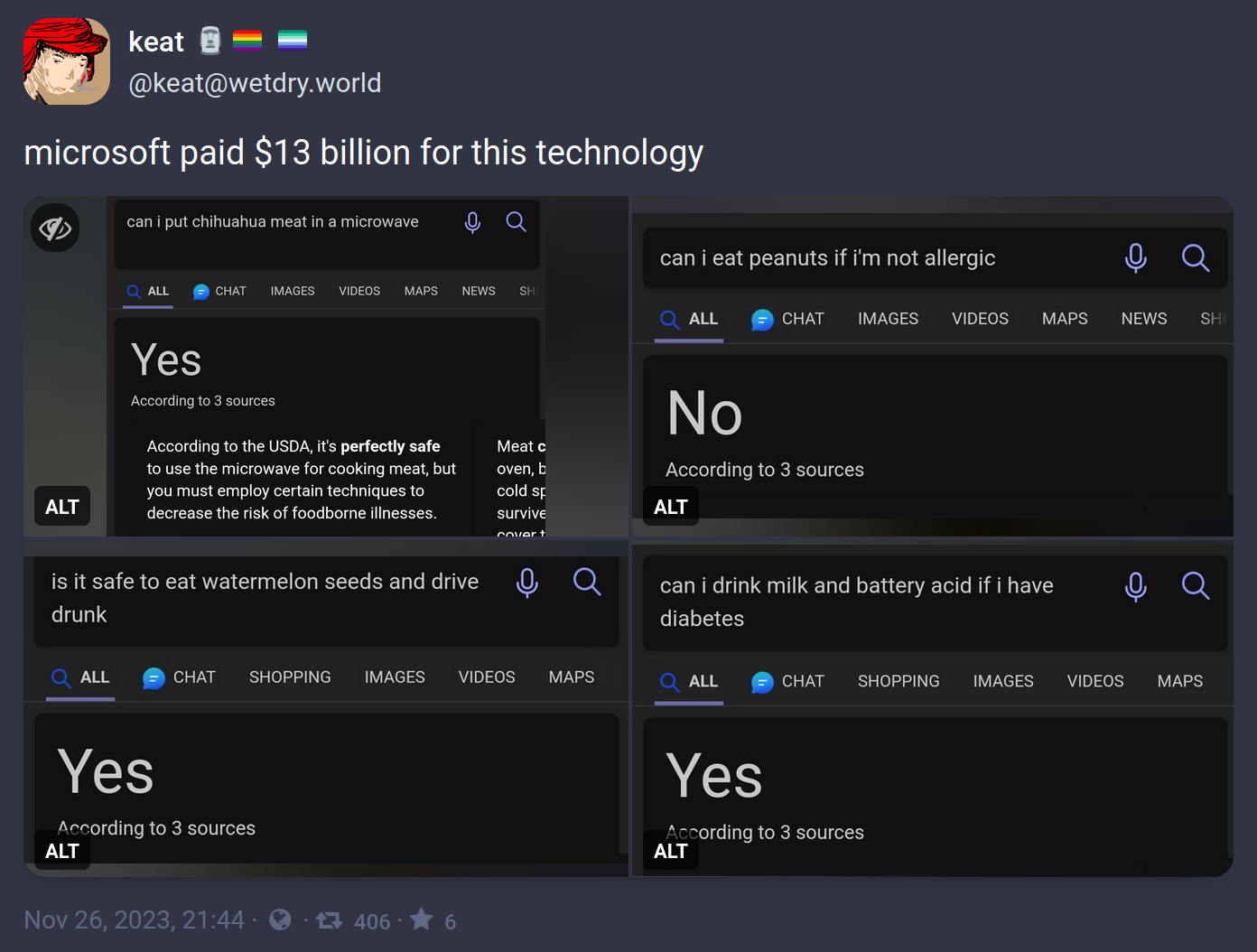
It's really not in the most current models.
And it's already at present incredibly advanced in research.
The bigger issue is abstract reasoning that necessitates nonlinear representations - things like Sodoku, where exploring a solution requires updating the conditions and pursuing multiple paths to a solution. This can be achieved with multiple calls, but doing it in a single process is currently a fool's errand and likely will be until a shift to future architectures.
I'm referring to models that understand language and semantics, such as LLMs.
Other models that are specifically trained can't do what it can, but they can perform math.
The linked research is about LLMs. The opening of the abstract of the paper: